Google’s IoT Core Surprise!
I think it’s fair to say Google surprised a few people this week with the announcement that their IoT Core service was being retired on the 16th August 2023. A hyperscaler sunsetting a service is by no means unique, but what seems out of the norm here is Google has done so with IoT Core, a service that’s been available to customers for around 5 years and an important area underpinning so many things (connected cars, smart cities, etc), with no equivalent service in place to migrate to. The simple message provided that customers should contact their account teams was probably just adding insult to injury.
Customers using small provider niche cloud services may have had some surprises in the past with companies going into administration and needing to move out of a service pretty damn quick, but I doubt (m)any Google customers saw this coming. With that one banner, Google has created technical debt for their customers and no doubt some large scale migration projects for some of their customers, with a year to get it done before it’s turned off. I’ve seen it suggested that the impact may not just be limited to changing the central IoT Core platform, but may also involve firmware needing to be replaced on the managed devices.

It’s made me wonder whether this could be a watershed moment for Google’s IoT customers, Google’s wider customers, or indeed the industry as a whole. Will customers start to consider the hyperscaler Ts and Cs they’re signing up to in greater detail, particularly those that are signing multi-year enterprise agreements committing them to spend a certain amount of money with a hyperscaler in return for a healthy discount on list prices. Imagine being a large Google IoT Core customer who’s made a multi-year spend commitment, and now you’ve realised that Google can retire your primary service that you intended would make up a significant percentage of the commitment you’ve made. I imagine someone’s going to be going through their existing contract and future contracts to understand their exposure and be likely to ask for break clauses if a major service disappears.
AWS being the original public cloud service, has certainly had to retire a few services over the years. I’ve been using the AWS ecosystem for just over 5 years and I can’t think of an instance like this. Of course, with age comes technical debt that can either be addressed by making incremental service improvements, or alternatively releasing a new service to run alongside or allowing the retirement of old service. When EC2 Classic, the original virtual machine service, was replaced with EC2 VPC (now just referred to as VPC), the two services ran alongside each other. Then EC2 classic was only available for existing customer accounts, before finally being retired for everyone, with customers being given some guidance on options for migrations and services like Cloud Endure / AWS Application Migration Service (MGN) being available to undertake large scale migrations. Landing Zone solutions was a slightly more tricky experience, with the original AWS Proserve Landing Zone solution being put into long term support (i.e. you can still use it, but it’s getting no new features), with the recommendation to use the Landing Zone as a Service Control Tower solution, however, quite some time passed before some prescriptive guidance on moving from one to the other was provided.
What can we do about it?
At this point, server huggers and people with half empty data centres will probably start screaming ‘lock in’ and talk about cloud repatriation. Personally, I find the term ‘lock in’ can make the topic rather emotive. It’s often used by people who have a solution to prevent you from being locked into the thing you were worried about, whilst then locking you into their solution (Cloud Management Platform tools offering to let you provision to multi-cloud for example). The reality is ‘lock in’ doesn't mean you can’t change something, it just means there’s work to do to enact that change.
That’s why I particularly like the term ‘Portability Time Objective’, which I think was coined by some more intelligent folk than me over at Red Hat. In my opinion, this removes the emotion from the topic. It really gets you thinking ‘if I had to move this application / service, how long am I willing for that to take?’, in a similar way that Recovery Point Objective (RPO) and Recovery Time Objective (RTO) make you think logically about your high availability / disaster recovery needs. This helps to avoid making expensive decisions that everything needs to be highly available regardless of the cost and leads to productive conversations about requirements and the cost implications of those requirements.

We can apply a similar concept to portability.
At one end of the spectrum, you have the native services from the Hyperscalers. These services remove the ‘undifferentiated heavy lifting’ from customers, allowing you to build solutions really quickly, have little to no management overhead and scalability and availability is provided for you within the bounds of certain SLAs. These services are typically pay per use, although some may have standing charges for being provisioned at a certain capacity, and are typically very cost effective. Operating in this way, for example, allowed Cazoo to rapidly enter the online car sales market, as well as seamlessly scale, and was a showcase at the AWS London Summit this year.
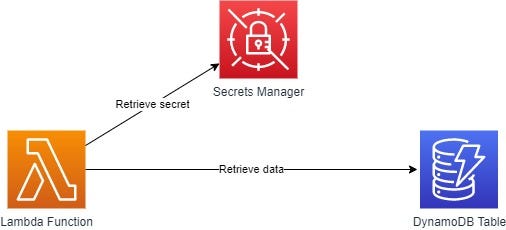
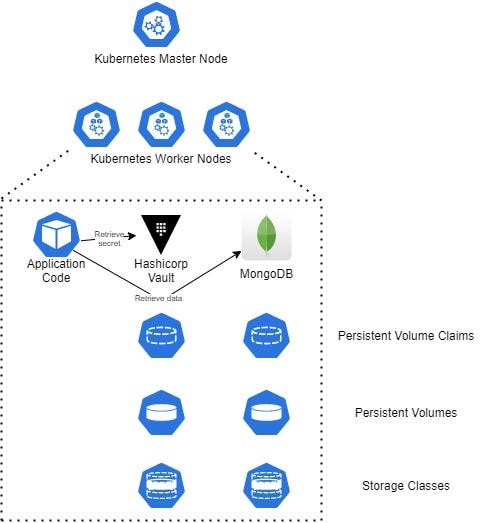
At the other end of the spectrum, we have fully container based services. When I say fully, I truly mean fully, no application workload in a container calling out to a DynamoDB table or AWS Secrets Manager, because to move it elsewhere, you’d have to update code to replace those services with the equivalent service from another provider. You need a secret management tool, deploy container based one, e.g. Hashicorp Vault. Want a NoSQL database? Deploy a container based one, e.g. MongoDB. You get the idea. If you want to take this to the extreme you could have the application either actively spread across multiple clouds so you can get your portability time down to zero. Of course this approach has its benefits for portability across hyperscalers, but it comes at the drawback of a longer time to value (you need to built and manage a platform like Red Hat OpenShift or Kubernetes), it has much more management overhead, you’re managing availability and scale, and the costs can soon ramp up. You’ve removed your ‘lock in’ from the hyperscaler (i.e. your PTO at that layer is now low / zero), but you’ve locked yourself into the Red Hat OpenShift or Kubernetes ecosystem, MongoDB and Hashicorp vault, in so much as you’re going to have to spend time doing work to replace API calls, deployment mechanisms etc. if you want to move yourself away from that in the future.
Of course, these are the two ends of the spectrum nothing stopping you evaluating things service by service and building some of your own whilst consuming some specific hyperscaler native services if you decide the value they provide is worth the time to port to something else later.
I’ve created a similar range to discuss solution options and the implications on time to value, management overhead and cost.

Hopefully, the above is useful and helps to explain why there is no right answer, and that you really need to think about your priorities, in a similar way to how you probably wrestle with RPO / RTO. I’m a huge fan of AWS’ managed services and like building and managing things with them. I worry that people who blindly buy into the ‘avoid lock in’ mantra are spending more time managing things, suffering performance degradation or worrying about scale, when they could be adding business value and are probably spending a significant amount that could be avoided if they spent time understanding what their portability requirement is. A halfway house might be to utilise a platform like AWS’ EKS platform, which would remove all of the Kubernetes cluster overhead, but still leave you with the need to manage what’s running on it.
Personally, I’ll always learn to use the hyperscaler native services if possible. AWS and others have invested billions in developing those services and unless you’ve got some overarching regulation etc. to be multi or hybrid with a near zero PTO I really think you’re missing out on the benefits those services offer and creating lots of complexity by architecting around using those solutions, as well as missing the integration between those services and other crucial services like IAM and encryption.

